








跟 NVIDIA 學 LLM 基礎!GPT、Transformer、attention、self-attention 機制、seq2seq 架構,紮穩大型語言模型的深度學習建模技術 (《跟 NVIDIA 學深度學習》修訂版)
-
型號/ISBN:9789863128342
品牌/出版社:旗標
製造商/作者:Magnus Ekman
-
上市日/出版日:2025-07-02
規格:平裝/17x23x2.5cm/416頁
數 量:
定價:$880元
特惠價:$669 元
VIP價:$651 元
-
配送方式: 超商、宅配
配送地區:台澎金馬
付款方式:ATM、信用卡、貨到付款、取貨付款
▍GPT、Transformer、attention / self-attention 機制、seq2seq 架構...,大型語言模型 (LLM) 背後的建模技術「硬派」揭密!
▍AI 界扛霸子 NVIDIA 的指定教材!
近年來,在 NVIDIA (輝達) GPU、CUDA 技術的推波助瀾下,大型語言模型 (LLM) 的發展有著爆炸性的成長,例如最為人知的 ChatGPT 正是運用深度學習 (Deep Learning) 技術打造而成的熱門 LLM 應用。
□【★徹底看懂 LLM 核心建模技術 - GPT、Transformer 的模型架構】
自從 ChatGPT 爆紅之後,LLM 建模技術一直是熱門的研究話題,ChatGPT 的背後核心是 GPT 模型,而 GPT 裡面最重要的技術就是最後那個「T」- 也就是大名鼎鼎、使用了 attention (注意力) 機制的 Transformer 模型,這當中所用的建模技術可說是一環扣一環,也容易讓初學者學起來暈得不得了,只要一個關鍵地方沒搞懂,後面就全花了...
為此,本書經過精心設計,是帶你看懂 GPT、Transformer、attention...這些 LLM 關鍵技術的最佳救星!本書設計了「環環相扣」的 NLP 章節內容,循序漸進介紹 LLM 的基礎建模技術:
看懂循環神經網路 (RNN、LSTM) 的缺點就知道為什麼需要 attention 機制以及 seq2seq 架構
看懂 attention 機制就能看懂 Transformer 的 self-attention 神經層
看懂 seq2seq 架構就能看懂 Transformer 的 encoder-decoder 架構
看懂 Transformer 就能看懂 GPT
你可以深刻感受到次一章的模型架構幾乎都是為了解決前一章模型的不足之處而誕生的,經此一輪學習下來,保證讓你對 GPT、Transformer、attention / self-attention 等技術清清楚楚!這絕對是其他書看不到的精彩內容!
【★學 LLM 基礎,跟 AI 重要推手 - NVIDIA 學最到位!】
NVIDIA 除了在硬體上為 AI 帶來助益外,為了幫助眾多初學者快速上手 LLM 用到的深度學習基礎,任職於 NVIDIA 的本書作者 Magnus Ekman 凝聚了他多年來在 NVIDIA 所積累的 AI 知識撰寫了本書。本書同時也是 NVIDIA 的教育和培訓部門 -【深度學習機構 (Deep Learning Institute, DLI)】 指定的培訓教材 (https://www.nvidia.com/zh-tw/training/books/)。
要學 LLM 基礎,跟 AI 重要推手 NVIDIA 學就對了!書中眾多紮實的內容保證讓你受益滿滿!
目錄:
Ch01 從感知器看神經網路的底層知識
1-1 最早的人工神經元 - Rosenblatt 感知器
1-2 增加感知器模型的能力
1-3 用線性代數實現神經網路模型
Ch02 梯度下降法與反向傳播
2-1 導數的基礎概念
2-2 以梯度下降法 (gradient descent) 對模型訓練問題求解
2-3 反向傳播 (back propagation)
Ch03 多層神經網路的建立與調校
3-1 動手實作:建立辨識手寫數字的多層神經網路
3-2 避免神經網路訓練成效不彰
3-3 實驗:調整神經網路與學習參數
Ch04 用卷積神經網路 (CNN) 進行圖片辨識
4-1 卷積神經網路 (CNN)
4-2 實作:以卷積神經網路做圖片分類
4-3 更深層的 CNN 與預訓練模型
Ch05 用循環神經網路 (RNN、LSTM...) 處理序列資料
5-1 RNN 的基本概念
5-2 RNN 範例:預測書店銷售額
5-3 LSTM (長短期記憶神經網路)
5-4 LSTM 範例:文字的 Auto-Complete 機制
Ch06 自然語言處理的重要前置工作:建立詞向量空間
6-1 詞向量、詞向量空間的基本知識
6-2 做法(一):在神經網路建模過程中「順便」生成詞向量空間
6-3 做法(二):以 word2vec、GloVe 專用演算法生成詞向量空間
Ch07 用機器翻譯模型熟悉 seq2seq 架構
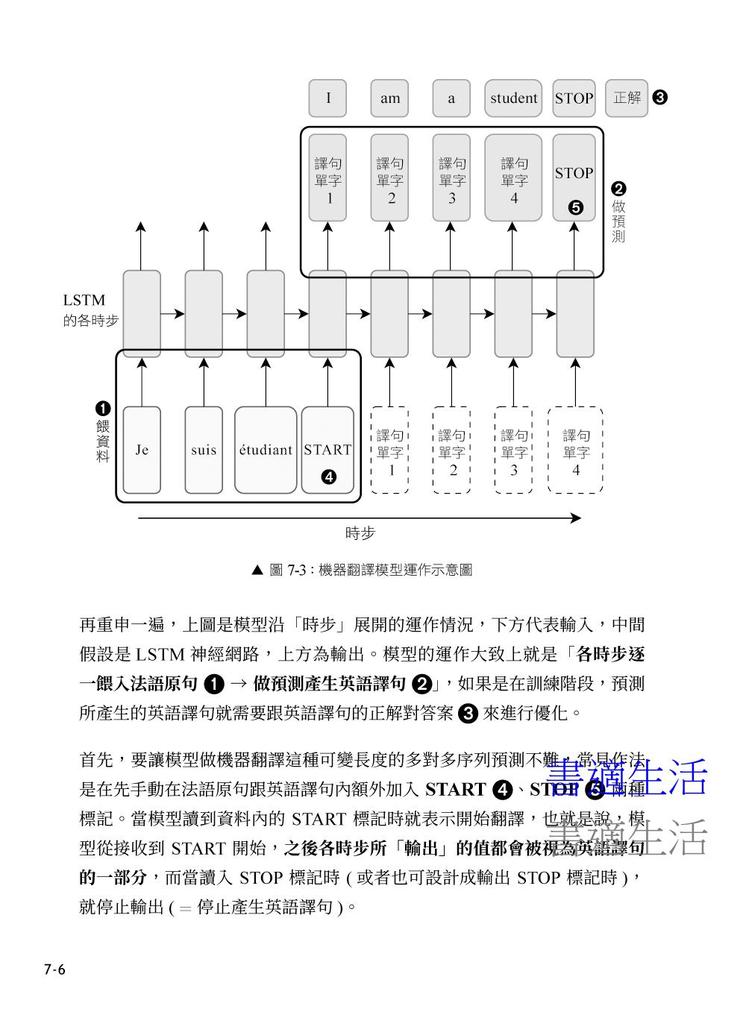
7-1 機器翻譯模型的基本知識
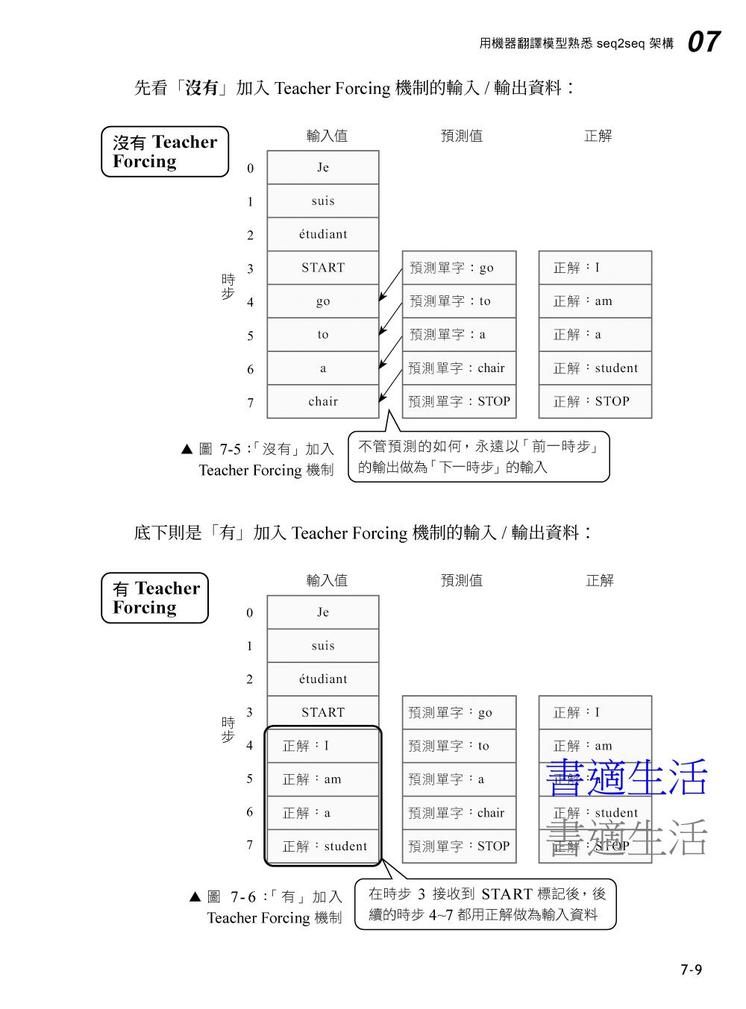
‧seq2seq 機器翻譯的運作概念
‧在訓練時導入 Teacher Forcing 機制
‧以編碼器-解碼器架構 (encoder-decoder architecture) 來建構 seq2seq 模型
7-2 機器翻譯的範例實作
Ch08 認識 attention 與 self-attention 機制
8-1 熟悉 attention 機制
‧從 q-k-v 的角度看關聯性分數向量的計算
8-2 認識 self-attention 機制
‧self-attention 的基本概念
‧self-attention 機制的算法
‧multi-head (多頭) 的 self-attention 機制
Ch09 Transformer、GPT 及其他衍生模型架構
9-1 Transformer 架構
9-1-1 編碼器端的架構
9-1-2 解碼器端的架構
9-1-3 Transformer 內的其他設計
9-1-4 小編補充:觀摩 keras 官網上的 Transformer 範例
9-2 Transformer 架構的衍生模型:GPT、BERT
9-2-1 認識 GPT 模型
9-2-2 認識 BERT 模型
9-2-3 其他從 Transformer 衍生出的模型
附錄 A 延伸學習 (一):多模態、多任務...等模型建構相關主題
附錄 B 延伸學習 (二):自動化模型架構搜尋
附錄 C 延伸學習 (三):後續學習方向建議
附錄 D 使用 Google 的 Colab 雲端開發環境


用 AI 做設計:沒時間?沒素材?沒靈感?就 Call AI 救援
定價 $599元
優惠價 $455元
VIP價 $443元

最新 Java 程式語言 修訂第七版
定價 $680元
優惠價 $530元
VIP價 $510元

威力導演21影片編輯動手做
定價 $399元
優惠價 $303元
VIP價 $295元

Inkscape+Tinkercad 2D/3D動手畫
定價 $399元
優惠價 $303元
VIP價 $295元

30個必學的AI行政工作術:搞定會議、行程、簡報、文書、圖表、影音、資料庫,事半功倍,準時下班!
定價 $480元
優惠價 $350元
VIP價 $336元

輕課程 寓教於樂 AI人工智慧概念含特徵小偵探桌遊包-最新版-附MOSME行動學習一點通:診斷
定價 $990元
優惠價 $842元
VIP價 $782元

【五南書展】網頁設計手冊(下):網站開發案例實作
定價 $450元
優惠價 $333元
VIP價 $315元

Photoshop新手操作指南
定價 $450元
優惠價 $338元
VIP價 $329元

Python 教學手冊
定價 $650元
優惠價 $510元
VIP價 $488元

Python 技術者們:實踐!帶你一步一腳印由初學到精通 (第二版)
定價 $650元
優惠價 $501元
VIP價 $488元